There’s a recurring narrative in tech circles: AI is about to replace software engineers. The argument usually goes — LLMs can write code, they can fix bugs, and they’re getting better every month. Why hire a human?
ProgramBench, a new benchmark from Meta FAIR and Stanford researchers, is a cold bucket of water on that narrative. And more importantly, it inadvertently makes one of the strongest cases I’ve seen for why software engineering is a genuinely difficult discipline — not just typing, but thinking.
What ProgramBench Actually Tests
The premise is elegant and brutal. Researchers take real, widely-used open-source software — FFmpeg, SQLite, the PHP interpreter, ripgrep, fzf — strip out all the source code, and give an AI agent only two things: the compiled executable and its documentation.
The agent’s job? Rebuild the program from scratch. Same behavior. All tests pass.
No hints. No scaffolding. No skeleton to fill in. Just the observable behavior of a working program and the task of re-engineering it.
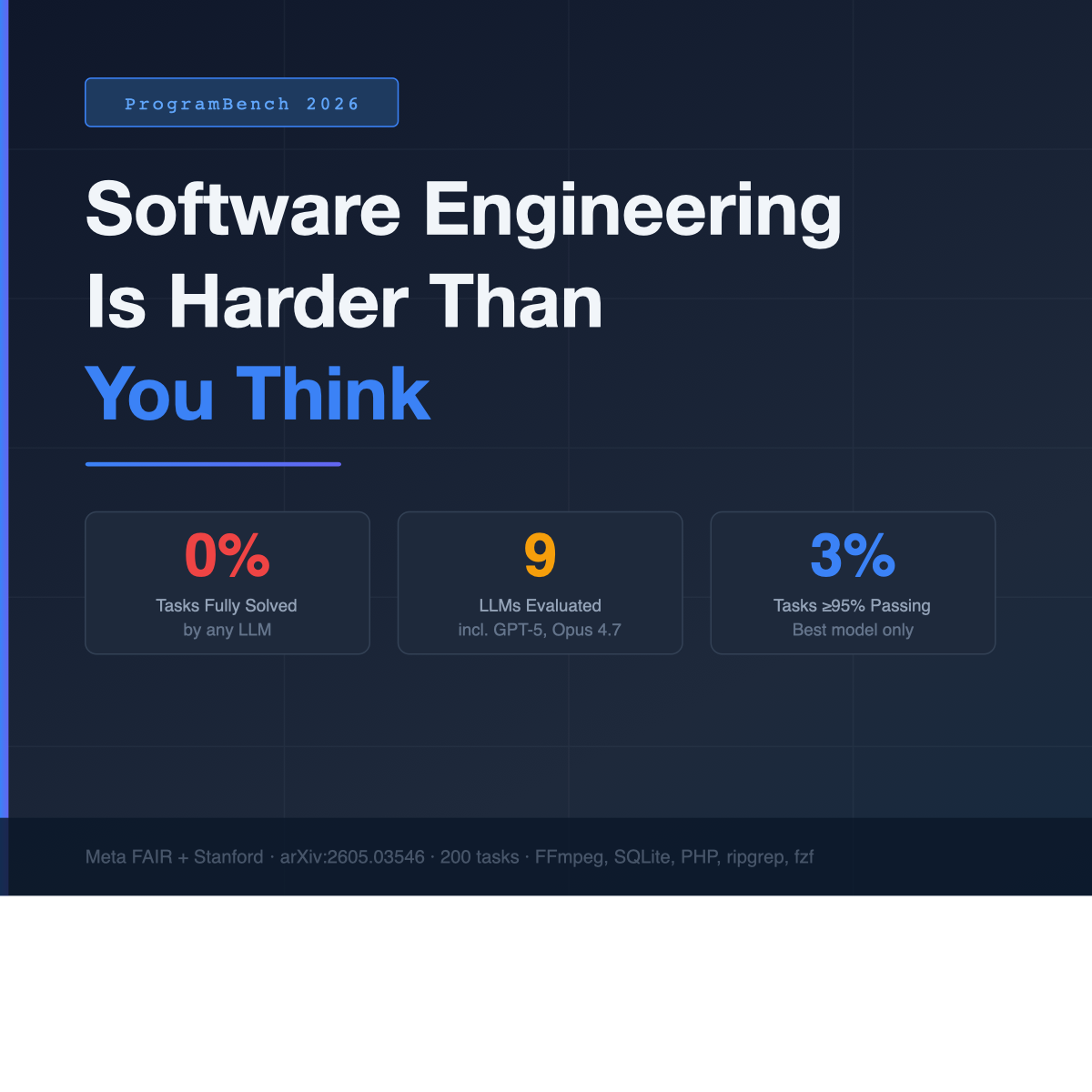
They tested 9 of the best LLMs available today — Claude Opus 4.7, Gemini 3.1 Pro, GPT 5.4, and others. The results:
No model fully resolved even one task. Zero.
The best result was Claude Opus 4.7 passing 95%+ of tests on a mere 3% of tasks. On complex systems like FFmpeg and the PHP interpreter, models scored near zero across the board.
Why This Matters More Than You’d Expect
At first glance, this sounds like a benchmark limitation story. “Of course AI can’t pass every edge case — the tests are too strict.” But the research design closes that loophole deliberately.
The models had full access to the gold executable. They could run it, probe it, test any input against it. Any behavior a test expects was fully discoverable. This isn’t a game of incomplete information.
What the models failed at wasn’t execution — it was architecture and design.
The researchers found a consistent pattern: AI models favor monolithic, single-file implementations with long functions. Human-written codebases, by contrast, are modular, layered, and decomposed into coherent abstractions.
That gap isn’t a coding gap. It’s a thinking gap.
What Software Engineering Actually Is
ProgramBench surfaces something that experienced engineers already know but rarely articulate clearly: software engineering is mostly decision-making, not code-writing.
Before a line of code is written on any serious project, a developer is asking questions like:
- What language and build system fit this problem?
- How should the codebase be organized so it can grow?
- What data structures represent the core entities cleanly?
- How do errors propagate and get communicated to users?
- What can be abstracted into reusable modules, and what should stay explicit?
These decisions compound. A bad abstraction choice in week one creates drag in month six. A monolithic file structure that seems fine at 200 lines becomes a maintenance nightmare at 2,000. Good software architecture is fundamentally about managing complexity over time — and that requires understanding not just what the code does now, but what it will need to do, and who else will need to read and change it.
Current AI models, even the best ones, don’t reason this way. They produce working code for the immediate problem. They don’t project forward, don’t reason about coupling and cohesion, and when left to their own choices — as ProgramBench forces them to be — they default to naive monolithic approaches that diverge sharply from how humans actually build sustainable software.
The Spectrum of Difficulty
ProgramBench covers 200 tasks, and the difficulty spread is illuminating. Simple CLI tools — small utilities like nnn, fzf, gron — see higher pass rates. Complex systems with deep architectural requirements — language interpreters, databases, media frameworks — are essentially unsolvable.
This maps directly to real-world complexity. A script that processes CSV files is genuinely a different kind of problem than designing a relational database engine. One requires implementing logic; the other requires understanding and recreating an ecosystem of design decisions made across years by hundreds of contributors.
The implication: AI tools are genuinely useful for well-scoped, bounded tasks. They get weaker as problem scope expands and as the number of compounding architectural decisions grows. Software engineering at scale is almost entirely in that second category.
Why This Is Actually Encouraging
This isn’t doom and gloom for software engineers. It’s a clarification.
The narrative that LLMs would replace engineers always suffered from conflating code generation with software engineering. Writing code is one part of the job. Understanding systems, making design tradeoffs, reasoning about maintainability, communicating architecture to a team — these aren’t auxiliary skills. They’re the core of what makes a senior engineer worth ten times what a junior engineer is worth.
ProgramBench quantifies what senior engineers have always known empirically: the hard part of software isn’t the syntax. It’s the design. It’s the judgment calls. It’s the ability to look at a complex system and decide how to decompose it into pieces that will remain comprehensible under change.
LLMs can accelerate implementation. They can handle boilerplate and scaffolding. They’re useful pair-programming partners for bounded problems. But as ProgramBench demonstrates, they still can’t do what a senior engineer does when facing a clean slate: reason through the architecture, make principled design decisions, and build something that’s not just functional today but maintainable tomorrow.
The Road Ahead
The ProgramBench authors note that their benchmark is deliberately extensible. As models improve, the benchmark can grow with more complex tasks. Right now, it serves as a hard ceiling on current AI capability for holistic software development.
That ceiling is lower than the hype suggests. The gap between “can write a function” and “can architect a system” remains wide. Closing it will require models that don’t just generate code — they need to develop something closer to engineering judgment.
Until then, software engineering remains a deeply human discipline. Not because humans are better at typing, but because good software is the product of design thinking that AI hasn’t cracked yet.
ProgramBench: Can Language Models Rebuild Programs From Scratch? — Yang et al., Meta FAIR / Stanford, arXiv:2605.03546 (May 2026)
 Anthropic Committed $1.8 Billion to Akamai's Edge GPU Infrastructure
Anthropic Committed $1.8 Billion to Akamai's Edge GPU Infrastructure
Click to load Disqus comments